Actualmente el grupo consta de las siguientes líneas estables de investigación:

Inteligencia Artificial en Salud. Computación fisiológica
Esta línea está centrada en la aplicación de técnicas de inteligencia artificial al diagnóstico y prevención de enfermedades y anomalías derivadas del sistema nervioso. En concreto se trabaja en la identificación de biomarcadores significativos y en el desarrollo de sistemas inteligentes para la detección de estados de estrés, diagnóstico temprano y pronóstico de la enfermedad de Parkinson, diagnóstico en la evolución del Alzheimer, predicción de ataques de epilepsia, entre otros.
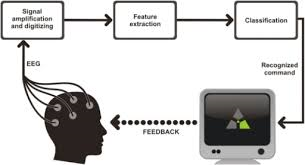
En cuanto a la computación fisiológica el grupo está especializado en el registro, análisis y uso de señales fisiológicas adquiridas de manera no invasiva. Además de desarrollar sistemas de registro lo menos invasivos posible (wearables), se proponen nuevos biomarcadores extraídos de dicha información fisiológica (ECG, EDA, EEG…) con el fin de proponer sistemas inteligentes para diagnosticar y/o prevenir dichas patologías.

Aprendizaje automático. Modelos explicativos y justos
En todas las líneas de investigación del grupo se persigue el objetivo de generar sistemas justos. Para conseguir este objetivo es necesario que los modelos utilizados sean explicativos.
En esta línea se diseñan y se trabaja con algoritmos de aprendizaje automático que pueden afrontar problemas en los que se requiere de, además de una eficiente clasificación, una explicación a la clasificación realizada; contribuyendo a la equidad de los sistemas generados. Para ello se utilizan estrategias que provienen de los clasificadores múltiples o ensembles. También se investiga en contextos en los que la cantidad de casos de alguna de las clases está muy desbalanceada con respecto al resto (class imbalance problem), lo que es un inconveniente para la mayoría de los paradigmas de aprendizaje automático.
Con respecto a la equidad, hacemos especial hincapié en el punto de vista de género, introduciendo metodologías que permiten generar sistemas libres de sesgos.

Antecedentes
Aunque las líneas mencionadas anteriormente reflejan la actividad actual del grupo ALDAPA, los antecedentes del grupo se remontan a los años 90 con una actividad investigadora inicial en torno al reconocimiento de patrones, la optimización y la computación paralela. Diversos paradigmas de clasificación supervisada y no supervisada –redes neuronales artificiales, clasificadores basados en vecindad (kNN), clasificadores múltiples, técnicas de agrupamiento o clustering, análisis de índices de validación– fueron aplicados en diversos ámbitos: detección de fallos en redes eléctricas; reconocimiento automático de caracteres (OCR, Optical Character Recognition); optimización de distribución de mercancías (TD-TSPTW, Time Dependent Traveling Salesman, Problem with Time Windows); predicción de fraude; fidelización de clientes; seguridad informática; modelado del comportamiento de usuarios, con discapacidad o no, interactuando con sistemas digitales (Web Mining, Sheltered Social Networks, eGovernment, eServices, eTourism); entre otros. También se ha trabajado en la computación de altas prestaciones en el contexto de la simulación de fenómenos físicos (interacción electrónica a nivel molecular, métodos Monte Carlo cinéticos, etc.), así como en computación federada y paralela.